

ハフマン木の符号化と復号化の実装
a. 問題分析
目標:
ハフマン木の符号化と復号化を実現する。
問題:
- ハフマン木の構築プロセスは正しいか?
- ハフマン符号は正しく生成されているか?
- ハフマン符号化と復号化のプロセスは正しく行われているか?
- 同じ頻度の文字を正しく処理できるか?
b. アルゴリズム設計
1. ハフマン木の構築:
- 入力テキストに基づいて文字の頻度を計算する。
- 優先度付きキュー(最小ヒープ)を使用してハフマン木を構築する。
入力: 文字頻度のマッピング frequencies。
出力: ハフマン木のルートノード root。
HuffmanNode* buildHuffmanTree(map<char, int>& frequencies) {
// 1. 優先度付きキュー(最小ヒープ)を作成してハフマン木を構築
priority_queue<HuffmanNode*, vector<HuffmanNode*>, CompareNodes> minHeap;
// 2. リーフノードを作成して最小ヒープに追加
for (auto& entry : frequencies) {
HuffmanNode* node = new HuffmanNode(entry.first, entry.second);
minHeap.push(node);
}
// 3. ハフマン木を構築
while (minHeap.size() > 1) {
HuffmanNode* left = minHeap.top();
minHeap.pop();
HuffmanNode* right = minHeap.top();
minHeap.pop();
HuffmanNode* internalNode = new HuffmanNode('$', left->frequency + right->frequency);
internalNode->left = left;
internalNode->right = right;
minHeap.push(internalNode);
}
// 4. ハフマン木のルートノードを返す
return minHeap.top();
}
2. ハフマン符号の生成:
- 再帰的にハフマン木を走査し、各文字のハフマン符号を生成する。
入力: ハフマン木のルートノード
root、空の文字列code、空のマッピングhuffmanCodes。 出力: 文字からハフマン符号へのマッピングhuffmanCodes。
void generateHuffmanCodes(HuffmanNode* root, string code, map<char, string>& huffmanCodes) {
// 1. 再帰終了条件:リーフノードに到達
if (root == nullptr) {
return;
}
// 2. リーフノードの場合、文字と対応するハフマン符号をマッピングに保存
if (root->data != '$') {
huffmanCodes[root->data] = code;
}
// 3. 左部分木と右部分木のハフマン符号を再帰的に生成
generateHuffmanCodes(root->left, code + "0", huffmanCodes);
generateHuffmanCodes(root->right, code + "1", huffmanCodes);
}
3. ハフマン符号化:
- 入力テキストを走査し、生成されたハフマン符号で各文字を置き換える。
入力: 元のテキスト
text、ハフマン符号のマッピングhuffmanCodes。 出力: 符号化されたテキストencodedText。
string huffmanEncode(string text, map<char, string>& huffmanCodes) {
string encodedText = "";
// 元のテキストを走査し、マッピングに基づいて各文字を置き換え
for (char c : text) {
encodedText += huffmanCodes[c];
}
return encodedText;
}
4. ハフマン復号化:
- ハフマン符号を走査し、符号の'0’と'1’に従ってハフマン木の左部分木または右部分木を訪問し、リーフノードに到達したらその文字を復号結果に追加する。
入力: 符号化されたテキスト
encodedText、ハフマン木のルートノードroot。 出力: 復号化されたテキストdecodedText。
string huffmanDecode(string encodedText, HuffmanNode* root) {
string decodedText = "";
HuffmanNode* current = root;
// ハフマン符号を走査
for (char bit : encodedText) {
// '0' と '1' に従って左部分木または右部分木を訪問
if (bit == '0') {
current = current->left;
} else {
current = current->right;
}
// リーフノードに到達した場合、文字を復号結果に追加し、ルートノードにリセット
if (current->data != '$') {
decodedText += current->data;
current = root;
}
}
return decodedText;
}
c. データ構造設計
- HuffmanNode 構造体:
- 文字、頻度、および左右の子ノードポインタを格納。
- CompareNodes 構造体:
- ノード比較のルールを定義し、最小ヒープを構築。
- std::priority_queue:
- HuffmanNode ポインタを格納する最小ヒープで、ハフマン木の構築に使用。
- std::map<char, int>:
- 文字頻度を格納。
d. デバッグプロセス
ハフマン木の構築:
- 頻度計算が正しいか確認。
- 最小ヒープの構築が期待通りに行われているか確認。
ハフマン符号の生成:
- 手動で一部の符号を計算し、生成されたハフマン符号が正しいか検証。
ハフマン符号化と復号化:
- 単純なテストケースを使用し、符号化と復号化の正しさを確認。
- 特に同じ頻度の文字の場合、その相対順序が変わらないことを確認。
e. 出力結果
プログラムを実行し、テストケース(例: “zhubingqianwoxihuanni” を入力)を使用して出力結果を確認。出力にはハフマン符号、符号化されたテキスト、復号化されたテキストが含まれ、その正しさを検証する。
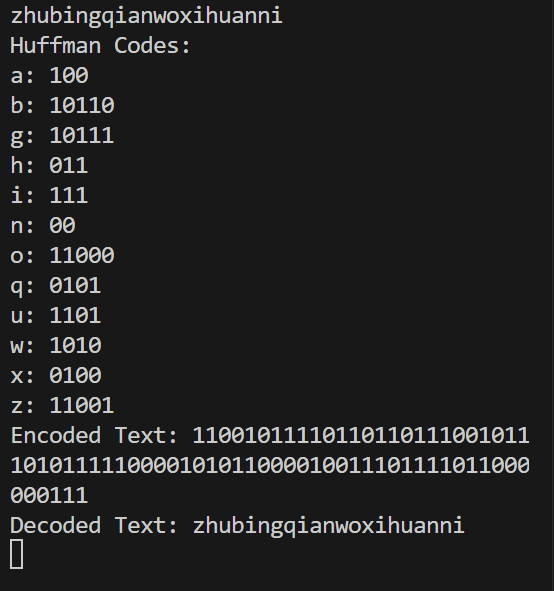
以下は入力textが"hello world"の場合の出力結果
Huffman Codes:
d: 00
r: 010
$: 011
w: 1000
e: 1001
o: 101
l: 110
h: 1110
: 1111
Encoded Text: 111000110010100010010010110111010010011110111100
Decoded Text: hello world
f. ソースコード
#include <iostream>
#include <queue>
#include <map>
#include <string>
using namespace std;
// ハフマン木のノード構造を定義
struct HuffmanNode {
char data;
int frequency;
HuffmanNode *left, *right;
HuffmanNode(char d, int freq) : data(d), frequency(freq), left(nullptr), right(nullptr) {}
};
// 2つのノードの優先度を比較
struct CompareNodes {
bool operator()(HuffmanNode* a, HuffmanNode* b) {//'+'演算子をオーバーロード
return a->frequency > b->frequency;
}
};
// ハフマン木を構築
HuffmanNode* buildHuffmanTree(map<char, int>& frequencies) {
priority_queue<HuffmanNode*, vector<HuffmanNode*>, CompareNodes> minHeap;
//優先度付きキューテンプレート、要素型HuffmanNode*、コンテナ型vector<HuffmanNode*>、比較規則関数CompareNodes
// リーフノードを作成し、最小ヒープに追加
for (auto& entry : frequencies) {//auto、entryの型をfrequenciesのキーと値のペアとして自動判定
HuffmanNode* node = new HuffmanNode(entry.first, entry.second);
minHeap.push(node);//キューに追加
}
//priority_queueは自動的にキューの優先度を維持
// ハフマン木を構築
while (minHeap.size() > 1) {//優先度付きキューにノードが1つだけ残ったらルートノード、ループ終了
HuffmanNode* left = minHeap.top();
minHeap.pop();
HuffmanNode* right = minHeap.top();
minHeap.pop();
HuffmanNode* internalNode = new HuffmanNode('$', left->frequency + right->frequency);
//2つの子ノードのルートノードを作成、frequencyは子ノードのfrequencyの合計
internalNode->left = left;
internalNode->right = right;
minHeap.push(internalNode);//このルートノードをminHeapに追加して再配置
}
//ハフマン木を生成、すべての非リーフノードのdataは'$'
// ルートノードを返す
return minHeap.top();
}
// 再帰的にハフマン符号を生成
void generateHuffmanCodes(HuffmanNode* root, string code, map<char, string>& huffmanCodes) {
if (root == nullptr) {
return;
}
if (root->data != '$') {//リーフノードに到達
huffmanCodes[root->data] = code;//この文字の符号はcode
}
generateHuffmanCodes(root->left, code + "0", huffmanCodes);
generateHuffmanCodes(root->right, code + "1", huffmanCodes);
//再帰的に実装、左部分木にアクセスすると+0、右部分木にアクセスすると+1
}
// ハフマン符号化
string huffmanEncode(string text, map<char, string>& huffmanCodes) {
string encodedText = "";//resultを空文字列で初期化
for (char c : text) {
encodedText += huffmanCodes[c];//文字cに対応するハフマン符号を追加
}
return encodedText;//結果を返す
}
// ハフマン復号化
string huffmanDecode(string encodedText, HuffmanNode* root) {
string decodedText = "";//復号結果を空文字列で初期化
HuffmanNode* current = root;
for (char bit : encodedText) {
if (bit == '0') {//'0'を読むと左部分木にアクセス、'1'を読むと右部分木にアクセス
current = current->left;
} else {
current = current->right;
}
if (current->data != '$') {//リーフノードに到達、このハフマン符号の復号結果を確定
decodedText += current->data;
current = root;//ルートノードに戻り、次の復号を続行
}
}
return decodedText;
}
int main() {
//string text = "hello world";
string text;
cin>>text;
map<char, int> frequencies;
// 文字頻度を計算
for (char c : text) {
frequencies[c]++;
}
// ハフマン木を構築
HuffmanNode* root = buildHuffmanTree(frequencies);
// ハフマン符号を生成
map<char, string> huffmanCodes;
generateHuffmanCodes(root, "", huffmanCodes);
// ハフマン符号を表示
cout << "Huffman Codes:" << endl;
for (auto& entry : huffmanCodes) {
cout << entry.first << ": " << entry.second << endl;//キーと値のペアを表示
}
// ハフマン符号化
string encodedText = huffmanEncode(text, huffmanCodes);
cout << "Encoded Text: " << encodedText << endl;
// ハフマン復号化
string decodedText = huffmanDecode(encodedText, root);
cout << "Decoded Text: " << decodedText << endl;
return 0;
}
まとめ
テストを通じて、プログラムがハフマン木の構築、符号化、復号化機能を正しく実装していることを確認。特に同じ頻度の文字の処理に注意し、その相対順序が変わらないことを確認。ハフマン木の構築時、最小ヒープを使用してノードを頻度の昇順で配置。
a 問題分析
本実験の目標は、ソート二分木に基づくノードの挿入、中間順走査、木全体の削除、および単一ノードの削除機能を実装することである。具体的な要求には、structを使用してノードを実装し、ノードの挿入と削除機能を実装することが含まれる。
b アルゴリズム設計
ノード挿入アルゴリズム設計
ノード挿入のアルゴリズムは再帰的アルゴリズムです。ノード値と現在のノード値を比較し、左部分木または右部分木に挿入します。現在の部分木が空の場合、新しいノードを作成して返します。そうでない場合、挿入関数を再帰的に呼び出します。
TreeNode* insert(TreeNode* root, int val) {
if (root == nullptr) {
return new TreeNode(val);
}
if (val <= root->data) {
root->left = insert(root->left, val);
} else if (val > root->data) {
root->right = insert(root->right, val);
}
return root;
}
ソート二分木構築アルゴリズム設計
ソート二分木を構築するアルゴリズムでは、ノード挿入アルゴリズムを使用します。入力シーケンスを走査し、各要素に対してノード挿入関数を呼び出し、ルートノードを更新し続けることで、最終的にソート二分木を得ます。
TreeNode* buildTree(int input[], int size) {
TreeNode* root = nullptr;
for (int i = 0; i < size; ++i) {
root = insert(root, input[i]);
}
return root;
}
中間順走査アルゴリズム設計
中間順走査アルゴリズムは、ソート二分木のノード値を出力し、木の構築が正しいことを検証するために使用されます。
void inorderTraversal(TreeNode* node) {
if (node != nullptr) {
inorderTraversal(node->left);
cout << node->data << " ";
inorderTraversal(node->right);
}
}
木全体削除アルゴリズム設計
木全体を削除するアルゴリズムは再帰的アルゴリズムです。削除関数を再帰的に呼び出し、左部分木と右部分木を削除した後、現在のノードを削除します。
void deleteTree(TreeNode* node) {
if (node != nullptr) {
deleteTree(node->left);
deleteTree(node->right);
delete node;
}
}
単一ノード削除アルゴリズム設計
単一ノードを削除するアルゴリズムは再帰的アルゴリズムです。ノード値と削除対象の値を比較し、左部分木または右部分木で削除を行います。一致するノードが見つかった場合、3つのケース(子ノードがない場合、子ノードが1つの場合、子ノードが2つの場合)に分けて処理します。
TreeNode* deleteNode(TreeNode* root, int val) {
if (root == nullptr) {
return root;
}
// 一致するノードを見つける
if (val < root->data) {
root->left = deleteNode(root->left, val);
} else if (val > root->data) {
root->right = deleteNode(root->right, val);
} else {
// ノードに子がないか1つの子がある場合
if (root->left == nullptr) {
TreeNode* temp = root->right;
delete root;
return temp;
} else if (root->right == nullptr) {
TreeNode* temp = root->left;
delete root;
return temp;
}
// ノードに2つの子がある場合、右部分木の最小ノードを見つける
TreeNode* minRight = root->right;
while (minRight->left != nullptr) {
minRight = minRight->left;
}
// 最小ノードの値を現在のノードにコピー
root->data = minRight->data;
// 右部分木から最小ノードを削除
root->right = deleteNode(root->right, minRight->data);
}
return root;
}
// 単一ノード削除のインターフェース関数
TreeNode* deleteSingleNode(TreeNode* root, int val) {
TreeNode* nodeToDelete = findNode(root, val);
if (nodeToDelete != nullptr) {
root = deleteNode(root, val);
}
return root;
}
c データ構造設計
ノード構造
struct TreeNode {
int data;
TreeNode* left;
TreeNode* right;
TreeNode(int val) : data(val), left(nullptr), right(nullptr) {}
};
d デバッグプロセス
デバッグプロセスでは、まず deleteSingleNode 関数が正しく実行されることを確認します。特定のノードを削除した後、二分探索木のノード値を中順走査で検証し、削除操作の正確性を確認します。最後に、出力を通じて実装全体の正確性を検証します。
e 出力結果
入力シーケンス 7, 5, 9, 2, 5, 2, 6, 3, 7, 0 に対する実験の出力結果は以下の通りです:
ソート済み二分木: 0 2 2 3 5 5 6 7 7 9
ノード 3 を削除後のソート済み二分木: 0 2 2 5 5 6 7 7 9
単一ノード 5 を削除後のソート済み二分木: 0 2 2 6 7 7 9
この出力結果は、単一ノードを削除する機能が追加されていることを示し、ノード 5 を削除後に中間順走査でソート済み二分木のノード値を出力することで、削除操作の正しさを検証しています。
f ソースコード
#include <iostream>
using namespace std;
// 二分木ノードの定義
struct TreeNode {
int data;
TreeNode* left;
TreeNode* right;
TreeNode(int val) : data(val), left(nullptr), right(nullptr) {}
};
// ソート済み二分木にノードを挿入
TreeNode* insert(TreeNode* root, int val) {
if (root == nullptr) {
return new TreeNode(val);
}
if (val <= root->data) {
root->left = insert(root->left, val);
} else if (val > root->data) {
root->right = insert(root->right, val);
}
return root;
}
// 中間順走査
void inorderTraversal(TreeNode* node) {
if (node != nullptr) {
inorderTraversal(node->left);
cout << node->data << " ";
inorderTraversal(node->right);
}
}
// 木全体を削除
void deleteTree(TreeNode* node) {
if (node != nullptr) {
deleteTree(node->left);
deleteTree(node->right);
delete node;
}
}
// 値がvalのノードを検索
TreeNode* findNode(TreeNode* root, int val) {
if (root == nullptr || root->data == val) {
return root;
}
if (val < root->data) {
return findNode(root->left, val);
} else {
return findNode(root->right, val);
}
}
// 単一ノードを削除
TreeNode* deleteNode(TreeNode* root, int val) {
if (root == nullptr) {
return root;
}
// 一致するノードを検索
if (val < root->data) {
root->left = deleteNode(root->left, val);
} else if (val > root->data) {
root->right = deleteNode(root->right, val);
} else {
// ノードが1つまたは子を持たない場合
if (root->left == nullptr) {
TreeNode* temp = root->right;
delete root;
return temp;
} else if (root->right == nullptr) {
TreeNode* temp = root->left;
delete root;
return temp;
}
// ノードが2つの子を持つ場合、右部分木の最小ノードを検索
TreeNode* minRight = root->right;
while (minRight->left != nullptr) {
minRight = minRight->left;
}
// 最小ノードの値を現在のノードにコピー
root->data = minRight->data;
// 右部分木から最小ノードを削除
root->right = deleteNode(root->right, minRight->data);
}
return root;
}
// 単一ノード削除のインターフェース関数
TreeNode* deleteSingleNode(TreeNode* root, int val) {
TreeNode* nodeToDelete = findNode(root, val);
if (nodeToDelete != nullptr) {
root = deleteNode(root, val);
}
return root;
}
int main() {
int input[] = {7, 5, 9, 2, 5, 2, 6, 3, 7, 0};
TreeNode* root = nullptr;
// ソート済み二分木を構築
for (int i = 0; i < 10; ++i) {
root = insert(root, input[i]);
}
// ソート済み二分木を表示
cout << "ソート済み二分木: ";
inorderTraversal(root);
cout << endl;
// ノード3を削除後のソート済み二分木
int nodeToDelete = 3;
root = deleteNode(root, nodeToDelete);
cout << "ノード " << nodeToDelete << " を削除後のソート済み二分木: ";
inorderTraversal(root);
cout << endl;
// 単一ノード5を削除後のソート済み二分木
int singleNodeToDelete = 5;
root = deleteSingleNode(root, singleNodeToDelete);
cout << "単一ノード " << singleNodeToDelete << " を削除後のソート済み二分木: ";
inorderTraversal(root);
cout << endl;
// 木全体を削除
deleteTree(root);
return 0;
}
いつまた一杯の酒を飲み、細かい論文を議論するのか。